Splitting Large XML Files in Java
Last week I was asked to write something in Java that is able to split a single 30GB XML file into smaller parts of configurable file size. The consumer of the file is going to be a middle-ware application that has problems with the large size of the XML. Under the hood it uses some kind of DOM parsing technique that causes it to run out of memory after a while. Since it’s vendor based middle-ware, we are not able to correct this ourselves. Our best option is to create some pre-processing tool that will first split the big file in multiple smaller chunks before they are processed by the middle-ware.
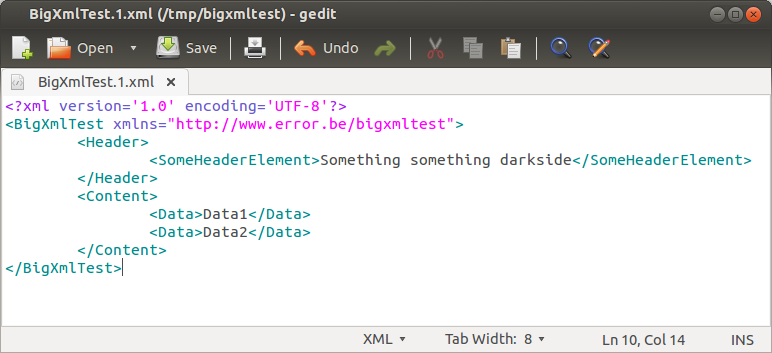
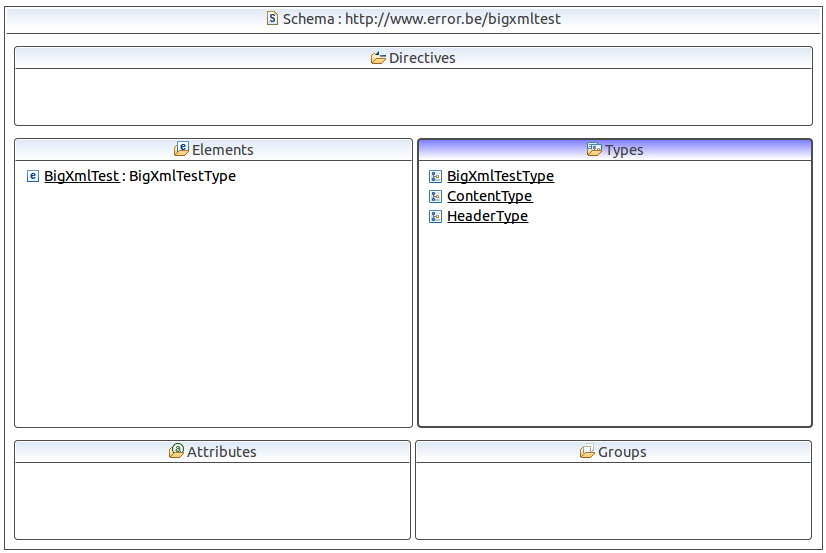
The XML file comes with a corresponding W3C schema, consisting of a mandatory header part followed by a content element which has several 0..* data elements nested. For the demo code I re-created the schema in simplified form:
 |  |
The header is neglectable in size. A single data element repetition is also pretty small, lets say less less then 50kB. The XML is so big because of the number of repetitions of the data element. The requirements are that:
- Each part of the splitted XML should be syntactical valid XML and each part should also validate against the original schema
- The tool should validate the XML against the schema and report any validation errors. Validation must not be blocking and non validating elements or attributes must not be skipped in the output
- For the header there is decided that rather then copying it in each of the new output files, the header will be re-generated for each new output file with some information of the processing and some defaults
So, using binary split tools such as Unix Split is out of the question. This will split after a fixed number of bytes leaving the XML corrupt for sure. I’m not really sure but tools such as Split don’t know anything about encoding either. So splitting after byte ‘x’ could not only result in splitting in the middle of an XML element (for example), but even in the middle of a character encoding sequence (when using Unicode that is UTF8 encoded for example). It’s clear we need something more intelligent.
XSLT as core technology is no go either. At first sight one could be tempted: using XSLT2.0 it is possible to create multiple output files from a single input file. It should even be possible to validate the input file while transforming. However, the devil is, as always, in the details. Otherwise simple operations in Java such as writing the validation error’s to a separate file, or checking the size of the current output file would probably require custom java code. This is certainly possible with Xalan and Saxon to have such extensions, but Xalan is not a XSLT2.0 implementation so that only leaves us with Saxon. Last but not least, XSLT1.0/2.0 are non-streaming, meaning that they will read the entire source document into memory, so this clearly excludes XSLT from the possibilities.
This leaves us with Java XML parsing as the only option left. The ideal candidate is in this case of course StAX. I’m not going into the SAX ↔ StAX comparison here, fact is that StAX is able to validate against schema’s (at least some parsers can) and can also write XML. Further more, the API’s is a lot easier to use then SAX, because it pull based it gives more control on iterating the document and works more pleasant then the push way of SAX. Aight, what do we need:
- StAX implementation capable of validating XML
- Oracle's JDK ships by default with SJSXP as the StAX implementation, but this one is however non validating; so I ended up with using Woodstox. As far as I could find, validation with Woodstox is only possible using the StAX cursor API
- Preferably have some Object/XML mapping technique for (re)creating the header instead of manually fiddling with elements and having to look up the correct datatypes/format
- Clearly JAXB. It has support for StAX, so you can create your Object model and then let it directly write to a StAX outputstream
The code is a bit to large to show it here as a whole. Both the source files, XSD and test XML can be accessed here on GitHub. It has a Maven pom file so you should be able to import it in your IDE of choice. The JAXB binding compiler will automatically compile the schema and put the generated sources on the classpath.
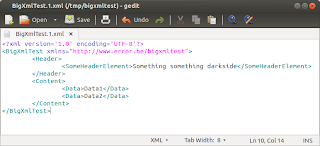
public void startSplitting() throws Exception {
XMLStreamReader2 xmlStreamReader = ((XMLInputFactory2) XMLInputFactory.newInstance())
.createXMLStreamReader(BigXmlTest.class.getResource("/BigXmlTest.xml"));
PrintWriter validationResults = enableValidationHandling(xmlStreamReader);
int fileNumber = 0;
int dataRepetitions = 0;
XMLStreamWriter xmlStreamWriter = openOutputFileAndWriteHeader(++fileNumber); // Prepare first file
The first line creates our StAX stream reader which means we are using the cursor API. The iterator API uses the XMLEventReader class. There is also a strange “2” in the classname which refers to the StAX 2 features from Woodstox, one of them is probably the support for validation. From here:
StAX2 is an experimental API that is intended to extend basic StAX specifications in a way that allows implementations to experiment with features before they end up in the actual StAX specification (if they do). As such, it is intended to be freely implementable by all StAX implementations same way as StAX, but without going through a formal JCP process. Currently Woodstox is the only known implementation.
“enableValidationHandling” can be seen in the source file if you want. I’ll highlight the important pieces. First, load the XML schema:
XMLValidationSchema xmlValidationSchema = xmlValidationSchemaFactory.createSchema(BigXmlTest.class
.getResource("/BigXmlTest.xsd"));
Callback for writing possible validation results to the output file;
public void reportProblem(XMLValidationProblem validationError) throws XMLValidationException {
validationResults.write(validationError.getMessage()
+ "Location:"
+ ToStringBuilder.reflectionToString(validationError.getLocation(),
ToStringStyle.SHORT_PREFIX_STYLE) + "\r\n");
}
The “openOutputFileAndWriteHeader” will create a XMLStreamWriter (which is again part form the cursor API, the iterator API has XMLEventWriter) to which we can output or part of the original XML file. It will also use JAXB to create our header and let it write to the output. The JAXB objects are generated default by using the Schema compiler (xjc).
private XMLStreamWriter openOutputFileAndWriteHeader(int fileNumber) throws Exception {
XMLOutputFactory xmlOutputFactory = XMLOutputFactory.newInstance();
xmlOutputFactory.setProperty(XMLOutputFactory.IS_REPAIRING_NAMESPACES, true);
XMLStreamWriter writer = xmlOutputFactory.createXMLStreamWriter(new FileOutputStream(new File(System
.getProperty("java.io.tmpdir"), "BigXmlTest." + fileNumber + ".xml")));
writer.setDefaultNamespace(DOCUMENT_NS);
writer.writeStartDocument();
writer.writeStartElement(DOCUMENT_NS, BIGXMLTEST_ROOT_ELEMENT);
writer.writeDefaultNamespace(DOCUMENT_NS);
HeaderType header = objectFactory.createHeaderType();
header.setSomeHeaderElement("Something something darkside");
marshaller.marshal(new JAXBElement<HeaderType>(new QName(DOCUMENT_NS, HEADER_ELEMENT, ""), HeaderType.class,
HeaderType.class, header), writer);
writer.writeStartElement(CONTENT_ELEMENT);
return writer;
}
On line 3 we enable “repairing namespaces”. The specification has this to say:
javax.xml.stream.isRepairingNamespaces: Function: Creates default prefixes and associates them with Namespace URIs. Type: Boolean Default Value: False Required: Yes
What I understand from this is that its required for handling default namespaces. Fact is that if it is not enabled the default namespace is not written in any way. On line 6 we set the default namespace. Setting it does not actually write it to the stream. Therefore one needs writeDefaultNamespace (line 9) but that can only be done after a start element has been written. So, you have to define the default namespace before writing any elements, but you need to write the default namespace after writing the first element. The rationale is that StAX needs to know if it has to generate a prefix for the root element you are going to write yes or no.
On line 8 we write the root element. Important to indicate to which namespace this element belongs. If you do not specify a prefix, a prefix will be generated for you, or, in our case no prefix will be generated at all because StAX knows we already set the default namespace. If you would remove the indication of the default namespace at line 6, the root element will be prefixed (with a random prefix) like: <wstxns1:BigXmlTest xmlns:wstxns1="http://www… Next we write our default namespace, this will be written to the element started previously (btw, for some deeper understanding on this order see this nice article). On line 11-14 we use our JAXB generated model to create the header and let our JAXB marshaller write it directly to our StAX output stream.
Important: the JAXB marshaller is initialized in fragment mode, otherwise it will start to add an XML declaration, as would be required for standalone documents, and that is of course not allowed in the middle of an existing document:
marshaller.setProperty(Marshaller.JAXB_FRAGMENT, true);
On a side note: the JAXB integration is not really useful in this example, it creates more complexity and takes more lines of code then simply adding the elements using the XMLStreamWriter. However, in if you have a more complex structure which you need to create and merge into the document it is pretty handy to have automatic object mapping.
So, we have our reader which is enabled for validation. From the moment we start iterating over the source document it will validate and parse at the same time. Then we have our writer which already has an initialized document and header written and is ready to accept more data. Finally we have to iterate over the source and write each part to the output file. If the output file becomes to big we will switch it with a new one:
while (xmlStreamReader.hasNext()) {
xmlStreamReader.next();
if (xmlStreamReader.getEventType() == XMLEvent.START_ELEMENT
&& xmlStreamReader.getLocalName().equals(DATA_ELEMENT)) {
if (dataRepetitions != 0 && dataRepetitions % 2 == 0) { // %2 = just for testing: replace this by for example checking the actual size of the current output file
xmlStreamWriter.close(); // Also closes any open Element(s) and the document
xmlStreamWriter = openOutputFileAndWriteHeader(++fileNumber); // Continue with next file
dataRepetitions = 0;
}
// Transform the input stream at current position to the output stream
transformer.transform(new StAXSource(xmlStreamReader), new StAXResult(
new FragmentXMLStreamWriterWrapper(new AvoidDefaultNsPrefixStreamWriterWrapper(xmlStreamWriter, DOCUMENT_NS))));
dataRepetitions++;
}
}
The important bits are that we keep iterating over the source document and check for the presence of the start of the Data element. If so we stream the corresponding element and its siblings to the output. In our simple example we don’t have siblings, just a text value. But if the structure is more complex all underlying nodes will automatically be copied to the output. Every two Data elements we will cycle our output file. The writer is closed and a new one is initialized (this check can of course be replaced by checking file size instead of % 2). If the writer is closed it will automatically take care of closing open elements and finally closing the document itself, no need to do this yourself. As what the mechanism is concerned for streaming the nodes from the input to the output:
- Because we are forced to use the cursor API because of the validation, we have to use XSLT to transfer the node and its siblings to the output. XSLT has some default templates which will be invoked if you do not specify an XSL specifically. In this case it will transform the input to the given output.
- A custom FragmentXMLStreamWriterWrapper is needed, I documented this in the JavaDoc. This wrapper is again wrapped in a AvoidDefaultNsPrefixStreamWriterWrapper. The reason for this last one is that the default XSLT template does not recognize the default namespace in our source document. More on that in a minute (or search for AvoidDefaultNsPrefixStreamWriterWrapper).
- The transformer that you use needs to be the Oracle JDK's internal version. Where we initialize the transformer we directly reference the instance of the internal TransformerFactory: com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl which then creates the correct transformer: transformer = new TransformerFactoryImpl().newTransformer(); Normally you would be using the TransformerFactory.newInstance() and use the transformer available on the classpath. However, parsers and transformers can install themselves by supplying META-INF/services. If another transformer (such as default Xalan, not the repackaged JDK version) would be on the classpath the transformation would fail. The reason is that apparently only the JDK internal version has the ability to transform from StAXSource to StAXResult
- The transformer will actually let our XMLStreamReader continue in the iteration process. So after a Data element has been processed, the cursor of the reader will be in theory ready at the next Data element. In theory that is, since the next event type might be a space if your XML is formatted. So it still might need some iterations on the xmlStreamReader.next() in our while loop before the next Data element is actually ready.
</ul>
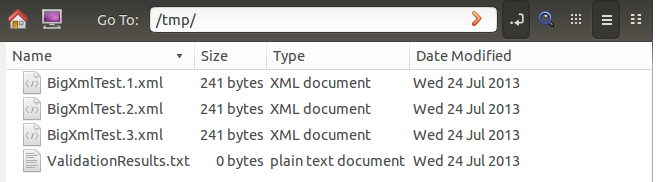
The result is that we have 3 output files, each compliant to the original schema, that have each 2 data elements:
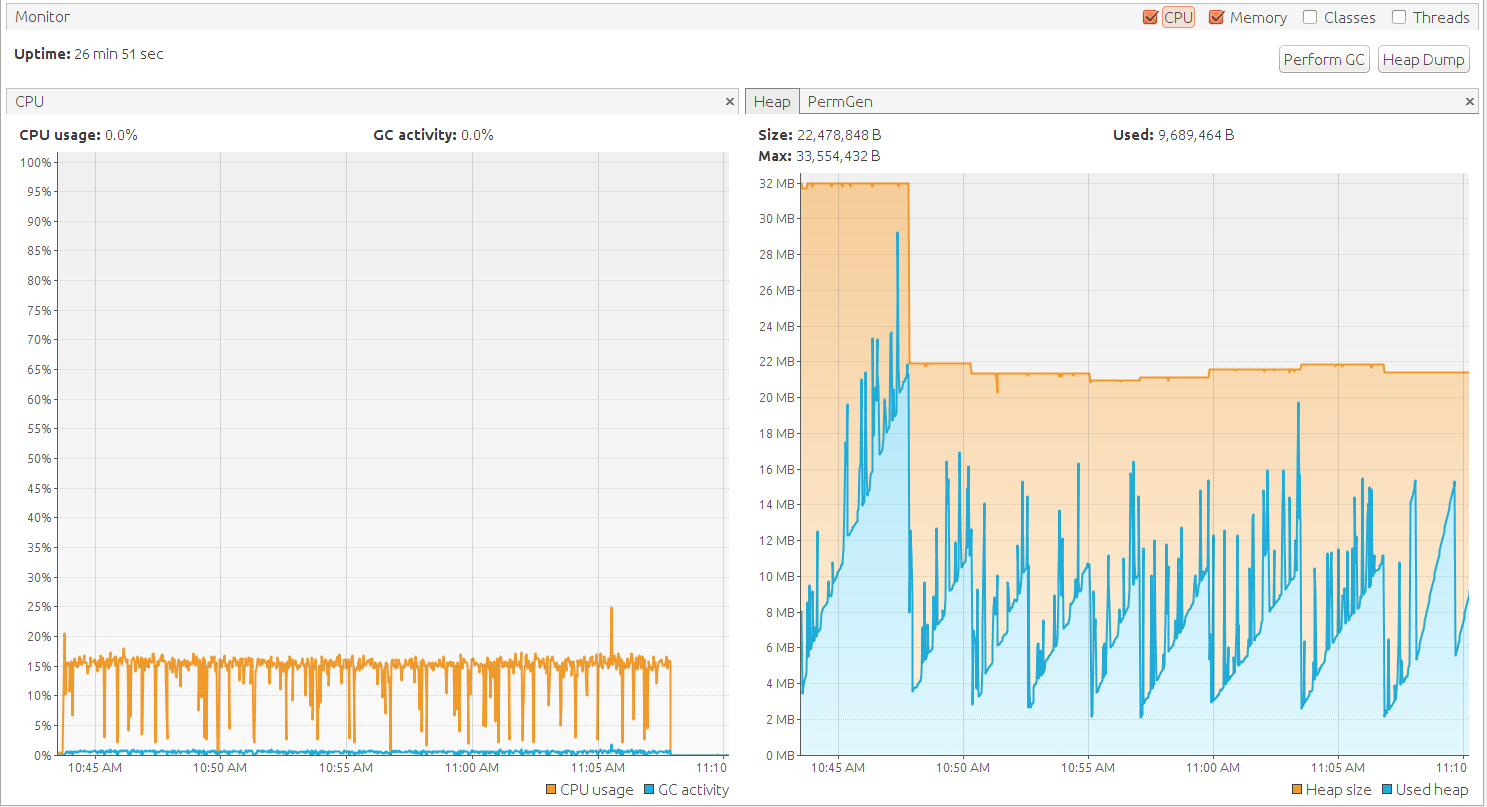
To split a ~30GB XML (I'm talking about my original assignment XML with a more complex structure, not the demo XSD used here) in parts of ~500MB with validation it took about 25 minutes. To test the memory usage I deliberately set the Xmx to 32MB. As you can see in the graph memory consumption is very low and there is no GV overhead:
 Life is good, but not completely. There where some awkward things that I discovered that one needs to be careful about. In my real scenario the input XML had no namespaces associated with it and I'm pretty sure it never will. That is the reason I stick with this solution. In the demo here there is a single namespace and that already starts to make the setup more brittle. The issue is not StAX: handling the namespaces with StAX is pretty simple. You can decide to have a default namespace (assuming your Schema is elementFormDefault = qualified) corresponding with the target namespace of the Schema and maybe declare some prefixed namespaces for possibly other namespaces that are imported in the Schema. The problems begin (as you might already noticed by now) when XSLT starts to interfere with the output stream. Apparently it doesn't check which namespaces are already defined or other things happen. The result is that they seriously clutter up the document by re-defining existing namespaces with other prefixes or resetting the default namespace and other stuff you don't want. One probably needs an XSL if you need more namespace manipulation then the default template. XSLT will also trigger exceptions if the input document is using default namespaces. It will try to register a prefix with name "xmlns". This is not allowed as xmlns is reserved for indicating the default namespace it cannot be used as a prefix. The fix I applied for this test was to ignore any prefix that is "xmlns" and to ignore the addition of the target namespace in cominbation with the xmlns prefix (thats why we have the AvoidDefaultNsPrefixStreamWriterWrapper). The prefix and namespace both need to match in the AvoidDefaultNsPrefixStreamWriterWrapper, because if you would have an input document without default namespace but with prefixes instead (like <bigxml:BigXmlTest xmlns:bigxml="http://...."><bigxml:Header....) then you cannot ignore adding the namespace (the combination will then be the target namespace with the "bigxml" prefix) since that would yield only prefixes for the data elements without namespaces being bound to them, for example:
Life is good, but not completely. There where some awkward things that I discovered that one needs to be careful about. In my real scenario the input XML had no namespaces associated with it and I'm pretty sure it never will. That is the reason I stick with this solution. In the demo here there is a single namespace and that already starts to make the setup more brittle. The issue is not StAX: handling the namespaces with StAX is pretty simple. You can decide to have a default namespace (assuming your Schema is elementFormDefault = qualified) corresponding with the target namespace of the Schema and maybe declare some prefixed namespaces for possibly other namespaces that are imported in the Schema. The problems begin (as you might already noticed by now) when XSLT starts to interfere with the output stream. Apparently it doesn't check which namespaces are already defined or other things happen. The result is that they seriously clutter up the document by re-defining existing namespaces with other prefixes or resetting the default namespace and other stuff you don't want. One probably needs an XSL if you need more namespace manipulation then the default template. XSLT will also trigger exceptions if the input document is using default namespaces. It will try to register a prefix with name "xmlns". This is not allowed as xmlns is reserved for indicating the default namespace it cannot be used as a prefix. The fix I applied for this test was to ignore any prefix that is "xmlns" and to ignore the addition of the target namespace in cominbation with the xmlns prefix (thats why we have the AvoidDefaultNsPrefixStreamWriterWrapper). The prefix and namespace both need to match in the AvoidDefaultNsPrefixStreamWriterWrapper, because if you would have an input document without default namespace but with prefixes instead (like <bigxml:BigXmlTest xmlns:bigxml="http://...."><bigxml:Header....) then you cannot ignore adding the namespace (the combination will then be the target namespace with the "bigxml" prefix) since that would yield only prefixes for the data elements without namespaces being bound to them, for example: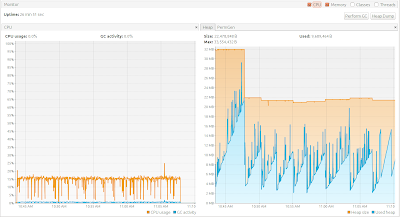
<?xml version='1.0' encoding='UTF-8'?> <BigXmlTest xmlns="http://www.error.be/bigxmltest"> <Header> <SomeHeaderElement>Something something darkside</SomeHeaderElement> </Header> <Content> <bigxml:Data>Data1</bigxml:Data> <bigxml:Data>Data2</bigxml:Data> </Content> </BigXmlTest>
Remember that the producer of the XML is free (again in case elementFormDefault = qualified) to choose whether to use the defaultnamespace or to prefix every element. The code should transparently be able to deal with both scenario's. The AvoidDefaultNsPrefixStreamWriterWrapper code for convenience:public class AvoidDefaultNsPrefixStreamWriterWrapper extends XMLStreamWriterAdapter { ... @Override public void writeNamespace(String prefix, String namespaceURI) throws XMLStreamException { if (defaultNs.equals(namespaceURI) && "xmlns".equals(prefix)) { return; } super.writeNamespace(prefix, namespaceURI); } @Override public void setPrefix(String prefix, String uri) throws XMLStreamException { if (prefix.equals("xmlns")) { return; } super.setPrefix(prefix, uri); }Finally, I also wrote a version (click here for GitHub) that does the exact same thing but this time with the StAX iterator API. You will notice that there no longer the cumbersome XSLT required for streaming to the output. Each Event of interest is simply added to the output. The lack of validation could be solved by first validating the input using the cursor API and then parse it using the Iterator API. It will take longer, but that might still be acceptable in most conditions. The most important piece:while (xmlEventReader.hasNext()) { XMLEvent event = xmlEventReader.nextEvent(); if (event.isStartElement() && event.asStartElement().getName().getLocalPart().equals(CONTENT_ELEMENT)) { event = xmlEventReader.nextEvent(); while (!(event.isEndElement() && event.asEndElement().getName().getLocalPart() .equals(CONTENT_ELEMENT))) { if (dataRepetitions != 0 && event.isStartElement() && event.asStartElement().getName().getLocalPart().equals(DATA_ELEMENT) && dataRepetitions % 2 == 0) { // %2 = just for testing: replace this by for example checking the actual size of the current // output file xmlEventWriter.close(); // Also closes any open Element(s) and the document xmlEventWriter = openOutputFileAndWriteHeader(++fileNumber); // Continue with next file dataRepetitions = 0; } // Write the current event to output xmlEventWriter.add(event); event = xmlEventReader.nextEvent(); if (event.isEndElement() && event.asEndElement().getName().getLocalPart().equals(DATA_ELEMENT)) { dataRepetitions++; } } } }On line 2 you will see that we get an XMLEvent back which contains all information about the current node. On line 4 you see that it is easier to use this form to check for the element type (instead of comparing with constants you can use the object model). On line 19 to copy the element from input to output we simply add the Event to the XMLEventWriter.